Algorithmes de chiffrement faible
1. Algorithmes de chiffrement faible (facilement déchiffrables)
Les premiers algorithmes utilisés pour le chiffrement d’une information étaient assez rudimentaires dans leur ensemble. Ils consistaient notamment au remplacement de caractères par d’autres. La confidentialité de l’algorithme de chiffrement était donc la pierre angulaire de ce système.
Exemples d’algorithmes de chiffrement faibles :
- ROT13 (rotation de 13 caractères, sans clé) ;
- Chiffre de César (décalage de plusieurs lettres dans l’alphabet sur la gauche ou sur la droite).
- Chiffre de Vigenère (introduit la notion de clé)
Exercices avec des algorithme faibles
Pour s’amuser avec ces algorithmes vous pouvez vous référer aux sites https://asecuritysite.com/ ou http://www.cryptool-online.org/ ou encore, parmi d’autres ressources, la libraire python pycipher : http://pycipher.readthedocs.io/en/master/. Pour des exemples en Python on ira volontiers consulter https://github.com/TheAlgorithms/Python/tree/master/ciphers
On trouvera plus bas des exercices d’implémentation en Bash et en Python 3 de quelques algorithmes faibles.
- Projet traducteur de langage Geek
- Projet ROT13
- Projet chiffrement de César
- Projet chiffrement de Vigenère
2. Projet traducteur de langage Geek
2.1. Objectif
Programme qui traduit une phrase ou un mot en langage geek.
2.2. Dictionnaire Leet
dictionnary = {"A": "4", "B": "8", "C": "(", "D": ")", "E": "3", "F": "f",
"G": "6", "H": "#", "I": "1", "J": "j", "K": "k", "L": "|",
"M": "m", "N": "n", "O": "0", "P": "p", "Q": "q", "R": "2",
"S": "5", "T": "7", "U": "u", "V": "v", "W": "w", "X": "x",
"Y": "y", "Z": "z"}
2.3. Résultat attendu
python3 leetspeak.py
Enter message: Do you speek leet
Clear to coded: )0 y0u 5p33k |337
Coded to clear: DO YOU SPEEK LEET
2.4. En pratique
2.5. Solution
En Bash:
echo "Do you speek leet" \
| tr '[a-z]' '[A-Z]' \
| tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' '48()3f6#1jk|mn0pq257uvwxyz'
echo ")0 y0u 5p33k |337" \
| tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' '48()3f6#1jk|mn0pq257uvwxyz' \
| tr '[a-z]' '[A-Z]'
En Python 3 :
#!/usr/local/bin/python3
"""
Leetspeak translator
"""
dictionnary = {"A": "4", "B": "8", "C": "(", "D": ")", "E": "3", "F": "f",
"G": "6", "H": "#", "I": "1", "J": "j", "K": "k", "L": "|",
"M": "m", "N": "n", "O": "0", "P": "p", "Q": "q", "R": "2",
"S": "5", "T": "7", "U": "u", "V": "v", "W": "w", "X": "x",
"Y": "y", "Z": "z"}
def translation(input_string: str, encrypt: bool) -> str:
"""
https://en.wikipedia.org/wiki/Leet
>>> string0 = 'Do you speek leet'
>>> string1 = translation(string0, True)
>>> string1 == ')0 y0u 5p33k |337'
True
>>> string2 = translation(string1, False)
>>> string2 == string0.upper()
True
"""
input_string = input_string.upper()
if encrypt is True:
for key, value in dictionnary.items():
input_string = input_string.replace(key, value)
out = input_string
else:
for key, value in dictionnary.items():
input_string = input_string.replace(value, key)
out = input_string
return out
def main() -> None:
"""Main Function"""
string0 = input("Enter message: ")
string1 = translation(string0, True)
print("Clear to coded:", string1)
string2 = translation(string1, False)
print("Coded to clear: ", string2)
if __name__ == "__main__":
import doctest
doctest.testmod()
main()

3. Projet ROT13
3.1. Objectif
Encoder et décoder un texte grâce à l’algorithme ROT13.
3.2. Algorithme ROT13
ROT13 est un cas particulier du chiffrement de César qui a été développé dans la Rome antique.
Comme il y a 26 lettres (2×13) dans l’alphabet latin de base, ROT13 est son propre inverse ; c’est-à-dire que pour annuler ROT13, le même algorithme est appliqué, de sorte que la même action peut être utilisée pour l’encodage et le décodage.
ROT13 crée un écalage de chaque lettre de 13 vers la droite dans l’alphabet. Si les lettres de l’alphabet sont numérotées de 0 à 25, il s’agirait d’ajouter 13 à leur rang et de s’assurer qu’il reste compris entre 0 et 25 avec le modulo 26.
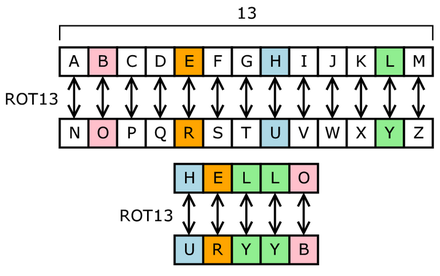
3.3. Résultat attendu
python rot13.py
Enter message: Hello World
Clear to coded: Uryyb Jbeyq
Coded to clear: Hello World
3.4. En pratique
3.5. Solution
En bash :
echo "Hello World" | tr '[A-Za-z]' '[N-ZA-Mn-za-m]'
echo "Uryyb Jbeyq" | tr '[N-ZA-Mn-za-m]' '[A-Za-z]'
En Python 3 :
#!/usr/local/bin/python3
"""ROT13 cipher"""
from string import ascii_lowercase, ascii_uppercase
def translation(input_string: str) -> str:
"""
https://en.wikipedia.org/wiki/ROT13
>>> string0 = 'Hello World'
>>> string1 = translation(string0)
>>> string1 == 'Uryyb Jbeyq'
True
>>> string2 = translation(string1)
>>> string2 == string0
True
"""
lower = ascii_lowercase
upper = ascii_uppercase
alphabet = lower + upper
key = 13
out = ""
for character in input_string:
if character in ascii_lowercase:
out += lower[(lower.index(character) + key) % len(lower)]
elif character in ascii_uppercase:
out += upper[(upper.index(character) + key) % len(upper)]
elif character not in alphabet:
out += character
return out
def main() -> None:
"""Main Function"""
string0 = input("Enter message: ")
string1 = translation(string0)
print("Clear to coded:", string1)
string2 = translation(string1)
print("Coded to clear: ", string2)
if __name__ == "__main__":
import doctest
doctest.testmod()
main()
Encore en python 3 :
rot13 = str.maketrans(
"ABCDEFGHIJKLMabcdefghijklmNOPQRSTUVWXYZnopqrstuvwxyz",
"NOPQRSTUVWXYZnopqrstuvwxyzABCDEFGHIJKLMabcdefghijklm")
"Hello World!".translate(rot13)
#'Uryyb Jbeyq!'
Et encore en python 3 :
import codecs
codecs.encode('Hello World!', 'rot_13')
4. Projet Caesar
4.1. Objectif
Encoder et décoder un texte grâce à l’algorithme de César. Mener une attaque Brute-Force pour découvrir le texte original.
4.2. Algorithme de César
En cryptographie, le chiffrement de César est l’une des techniques de chiffrement les plus simples et les plus connues. Il s’agit d’un type de chiffrement par substitution dans lequel chaque lettre du texte en clair est remplacée par une lettre située à un nombre fixe de positions dans l’alphabet. Par exemple, avec un décalage vers la gauche de 3, D est remplacé par A, E devient B, et ainsi de suite. La méthode doit son nom à Jules César, qui l’utilisait dans sa correspondance privée.
L’étape de chiffrement effectuée par un chiffre César est souvent incorporée dans des schémas plus complexes, tels que le chiffre de Vigenère, et a encore une application moderne dans le système ROT13.
4.3. Résultat attendu
python3 caesar.py
Enter message: Hello World
Enter a key (off-set): 13
Clear to coded: UryyB jBEyq
Coded to clear: Hello World
4.4. En pratique
4.5. Solution
En Bash:
K=13
A=$(echo {a..z} {A..Z} | sed -r 's/ //g')
C=$(echo $A | sed -r "s/^.{$K}//g")$(echo $A | sed -r "s/.{$( expr ${#A} - $K )}$//g")
echo "Hello World" | tr ${A} ${C}
echo "UryyB jBEyq" | tr ${C} ${A}
En Python 3 :
#!/usr/local/bin/python3
"""Caesar cipher"""
from string import ascii_letters
from typing import Dict
def translation(input_string: str, key: int = 13, encrypt: bool) -> str:
"""
https://en.m.wikipedia.org/wiki/Caesar_cipher
>>> string0 = 'Hello World'
>>> key = 13
>>> string1 = translation(string0, key, True)
>>> string1 == 'UryyB jBEyq'
True
>>> string2 = translation(string1, key, False)
>>> string2 == string0
True
"""
alphabet = ascii_letters
if encrypt is not True:
key *= -1
out = ""
for character in input_string:
if character not in alphabet:
out += character
else:
out += alphabet[(alphabet.index(character) + key) % len(alphabet)]
return out
def bruteforce(input_string: str) -> Dict[int, str]:
"""
https://en.wikipedia.org/wiki/Brute_force
>>> string0 = 'Hello World'
>>> key = 13
>>> string1 = translation(string0, key, True)
>>> bruteforce(string1)[key] == string0
True
"""
alphabet = ascii_letters
brute_force_data = {}
for key in range(1, len(alphabet) + 1):
brute_force_data[key] = translation(input_string, key, False)
return brute_force_data
def main() -> None:
"""Main Function"""
string0 = input("Enter message: ")
key = int(input("Enter a key (off-set): "))
string1 = translation(string0, key, True)
print("Clear to coded:", string1)
string2 = translation(string1, key, False)
print("Coded to clear: ", string2)
print(bruteforce(string1))
if __name__ == "__main__":
import doctest
doctest.testmod()
main()
5. Projet Vigenere
5.1. Objectif
Encoder et décoder un texte grâce à l’algorithme de Vigenère et une clé.
5.2. Algortithme de Vigenère
Pour casser le code de César il suffit de tester autant de décalages possibles qu’il n’y a de lettres dans l’alphabet.
L’algortithme de Vigenère consiste à introduire une clé rendant le décalage variable selon la position du caractère dans le message.
| Message clair | c | i | s | c | o | s | y | s | t | e | m | s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n# du message clair | 2 | 8 | 18 | 2 | 14 | 18 | 24 | 18 | 19 | 4 | 12 | 18 |
| Clé répétée | a | b | c | d | a | b | c | d | a | b | c | d |
| n# de clé (décalage) | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 |
| Résultat n# + n# | 2 | 9 | 20 | 5 | 14 | 19 | 0 | 21 | 19 | 5 | 14 | 21 |
| Message chiffré | c | j | u | f | o | t | a | v | t | f | o | v |
5.3. Résultat attendu
python vigenere.py
Enter message: ciscosystems
Enter a key: abcd
Clear to coded: cjufotAvtfov
Coded to clear: ciscosystems
5.4. En pratique
5.5. Solution
#!/usr/local/bin/python3
"""Vigenere cipher"""
from string import ascii_letters
def translation(input_string: str, key: str = 'abcd', encrypt: bool) -> str:
"""
https://en.wikipedia.org/wiki/Vigen%C3%A8re_cipher
>>> string0 = 'ciscosystems'
>>> encryption_key = 'abcd'
>>> string1 = translation(string0, encryption_key, True)
>>> string1 == 'cjufotAvtfov'
True
>>> string2 = translation(string1, encryption_key, False)
>>> string2 == string0
True
"""
alphabet = ascii_letters
out = ""
for index, character in enumerate(input_string):
key_index = alphabet.index(key[index % len(key)])
if encrypt is not True:
key_index *= -1
if character not in alphabet:
out += character
else:
out += alphabet[(alphabet.index(character)
+ key_index) % len(alphabet)]
return out
def main() -> None:
"""Main Fynction"""
string0 = input("Enter message: ")
encryption_key = input("Enter a key: ")
string1 = translation(string0, encryption_key, True)
print("Clear to coded:", string1)
string2 = translation(string1, encryption_key, False)
print("Coded to clear: ", string2)
if __name__ == "__main__":
import doctest
doctest.testmod()
main()
6. Cisco type 7 password
6.5. Solution
#!/usr/local/bin/python3
"""
Cisco IOS type 7 password encoder decoder (enable password, user password)
https://github.com/ilneill/Py-CiscoT7/blob/master/src/Py-CiscoT7.py
Each plaintext character is XOR'ed with a different character
from a well-knowed key.
The first character used from the key is determined by a random number offset
between 0 and 15.
This offset is pre-pended to the encrypted password as 2 decimal digits.
The offset is incremented as each character of the plaintext password
is encrypted.
The ASCII code of each encrypted character is appended to the
encrypted password as 2 hex digits.
A plaintext password has a permissible length of 1 to 25 characters.
"""
import random
# Cisco XOR key.
# The encryption/decryption key used by Cisco
# See https://www.gitmemory.com/issue/heyglen/network_tech/21/489420875
CISCO_KEY = 'dsfd;kfoA,.iyewrkldJKDHSUBsgvca69834ncxv9873254k;fg87'
xkey = [int(hex(ord(x)), 16) for x in CISCO_KEY]
def type7_encode(input_string):
"""doc"""
if 1 <= len(input_string) <= 25:
salt = random.randint(0, 15)
enc_pwd = format(salt, "02d")
for counter in range(0, len(input_string), 1):
enc_char = ord(input_string[counter]) \
^ xkey[(counter + salt) % len(CISCO_KEY)]
enc_pwd += format(enc_char, "02X")
else:
enc_pwd = "Error! Bad password length."
return enc_pwd
def type7_decode(enc_pwd):
"""doc"""
index = int(enc_pwd[:2])
enc_pwd = enc_pwd[2:].rstrip()
pwd_hex = [enc_pwd[x:x + 2] for x in range(0, len(enc_pwd), 2)]
cleartext = [chr(xkey[index+i] ^ int(pwd_hex[i], 16))
for i in range(0, len(pwd_hex))]
return ''.join(cleartext)
def test() -> None:
"""
test function
>>> string0 = 'password'
>>> string1 = type7_encode(string0)
>>> type7_decode(string1) == string0
True
>>> string2 = '095C4F1A0A1218000F'
>>> string2
'095C4F1A0A1218000F'
>>> type7_decode(string2) == string0
True
"""
def main() -> None:
"""Main Function"""
string0 = input("Enter message: ")
string1 = type7_encode(string0)
print("Clear to coded:", string1)
string2 = type7_decode(string1)
print("Coded to clear: ", string2)
if __name__ == "__main__":
import doctest
doctest.testmod()
main()
