Stockage LVM
1. Concepts RAID
On se contentera de parler ici des technologies RAID0, RAID1 et RAID5. On peut se référer à la source pour les autres types de RAID notamment combinés (RAID01, RAID10, …) : https://fr.wikipedia.org/wiki/RAID_(informatique)
Le RAID est un ensemble de techniques de virtualisation du stockage permettant de répartir des données sur plusieurs disques durs afin d’améliorer soit les performances, soit la sécurité ou la tolérance aux pannes de l’ensemble du ou des systèmes.
L’acronyme RAID a été défini en 1987 par l’Université de Berkeley, dans un article nommé A Case for Redundant Arrays of Inexpensive Disks (RAID), soit « regroupement redondant de disques peu onéreux ». Aujourd’hui, le mot est devenu l’acronyme de Redundant Array of Independent Disks, ce qui signifie « regroupement redondant de disques indépendants ».
Le système RAID est :
- soit un système de redondance qui donne au stockage des données une certaine tolérance aux pannes matérielles (ex : RAID1).
- soit un système de répartition qui améliore ses performances (ex : RAID0).
- soit les deux à la fois, mais avec une moins bonne efficacité (ex : RAID5).
Le système RAID est donc capable de gérer d’une manière ou d’une autre la répartition et la cohérence de ces données. Ce système de contrôle peut être purement logiciel ou utiliser un matériel dédié.
1.1. RAID 0 : volume agrégé par bandes
Le RAID 0, également connu sous le nom d’« entrelacement de disques » ou de « volume agrégé par bandes » (striping en anglais), est une configuration RAID permettant d’augmenter significativement les performances de la grappe en faisant travailler n disques durs en parallèle (avec n > ou = 2).
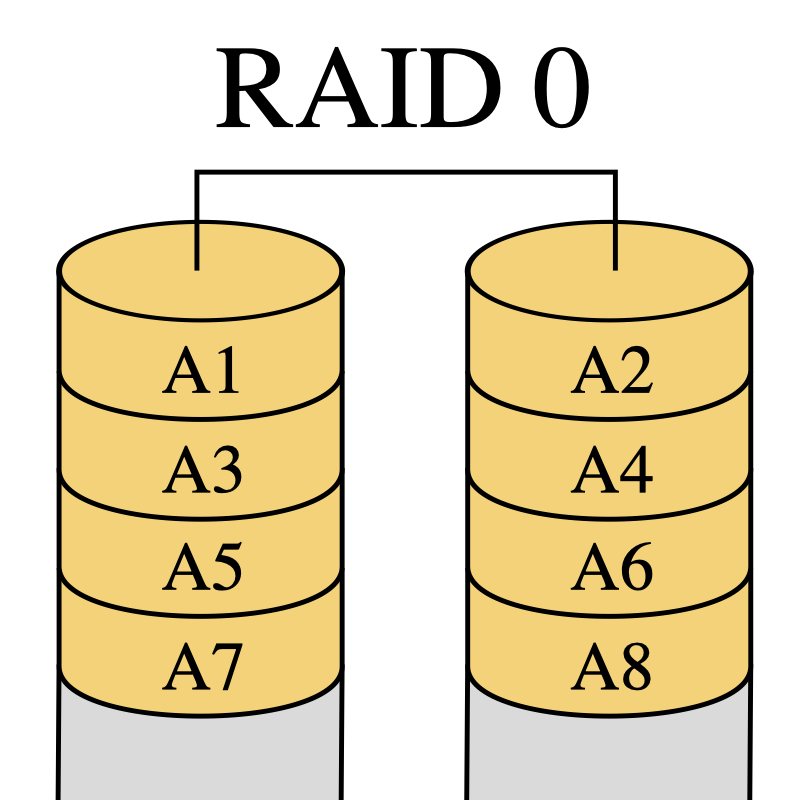
La capacité totale est égale à celle du plus petit élément de la grappe multiplié par le nombre d’éléments présent dans la grappe, car le système d’agrégation par bandes se retrouvera bloqué une fois que le plus petit disque sera rempli (voir schéma). L’espace excédentaire des autres éléments de la grappe restera inutilisé. Il est donc conseillé d’utiliser des disques de même capacité.
Le défaut de cette solution est que la perte d’un seul disque entraîne la perte de toutes ses données.
Dans un RAID 0, qui n’apporte aucune redondance, tout l’espace disque disponible est utilisé (tant que tous les disques ont la même capacité).
Dans cette configuration, les données sont réparties par bandes (stripes en anglais) d’une taille fixe. Cette taille est appelée granularité.
1.2. RAID 1 : Disques en miroir
Le RAID 1 consiste en l’utilisation de n disques redondants (avec n > ou = 2), chaque disque de la grappe contenant à tout moment exactement les mêmes données, d’où l’utilisation du mot « miroir » (mirroring en anglais).
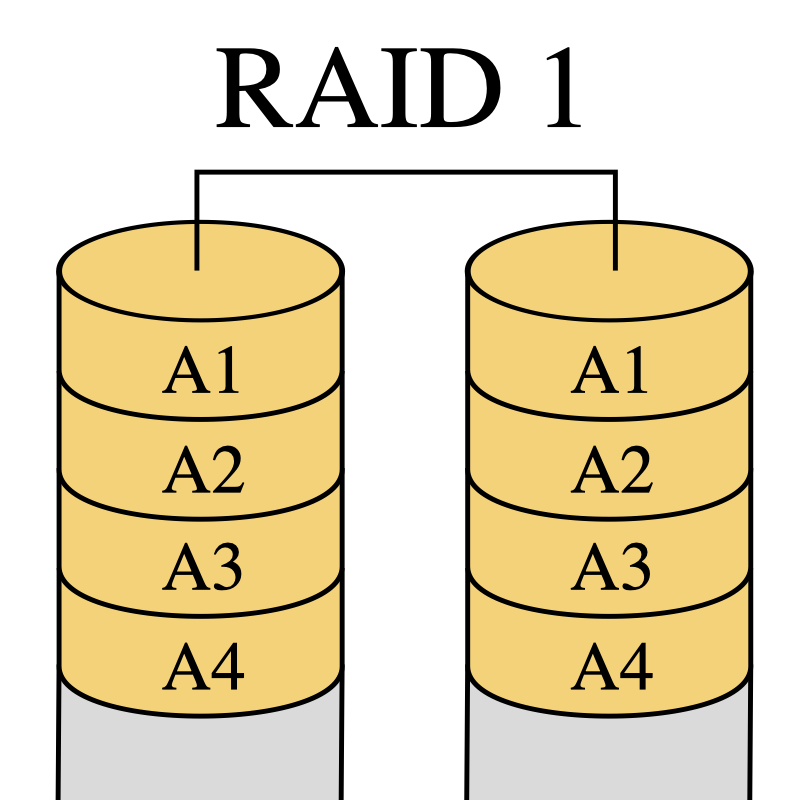
La capacité totale est égale à celle du plus petit élément de la grappe. L’espace excédentaire des autres éléments de la grappe restera inutilisé. Il est donc conseillé d’utiliser des éléments identiques.
Cette solution offre un excellent niveau de protection des données. Elle accepte une défaillance de n-1 éléments.
Les coûts de stockage sont élevés et directement proportionnels au nombre de miroirs utilisés alors que la capacité utile reste inchangée. Plus le nombre de miroirs est élevé, et plus la sécurité augmente, mais plus son coût devient prohibitif.
Les accès en lecture du système d’exploitation se font sur le disque le plus facilement accessible à ce moment-là. Les écritures sur la grappe se font de manière simultanée sur tous les disques, de façon à ce que n’importe quel disque soit interchangeable à tout moment.
Lors de la défaillance de l’un des disques, le contrôleur RAID désactive (de manière transparente pour l’accès aux données) le disque incriminé. Une fois le disque défectueux remplacé, le contrôleur RAID reconstitue, soit automatiquement, soit sur intervention manuelle, le miroir. Une fois la synchronisation effectuée, le RAID retrouve son niveau initial de redondance.
La migration du RAID1 vers RAID0, RAID5, RAID6 est presque toujours envisageable, ce qui fait du RAID1 une bonne solution de départ si on n’a pas un besoin de performance important.
1.3. RAID 5 : volume agrégé par bandes à parité répartie
Le RAID 5 combine la méthode du volume agrégé par bandes (striping) avec une parité répartie. Il s’agit là d’un ensemble à redondance N+1. La parité, qui est incluse avec chaque écriture se retrouve répartie circulairement sur les différents disques. Chaque bande est donc constituée de N blocs de données et d’un bloc de parité. Ainsi, en cas de défaillance de l’un des disques de la grappe, pour chaque bande il manquera soit un bloc de données soit le bloc de parité. Si c’est le bloc de parité, ce n’est pas grave, car aucune donnée ne manque. Si c’est un bloc de données, on peut calculer son contenu à partir des N-1 autres blocs de données et du bloc de parité. L’intégrité des données de chaque bande est préservée. Donc non seulement la grappe est toujours en état de fonctionner, mais il est de plus possible de reconstruire le disque une fois échangé à partir des données et des informations de parité contenues sur les autres disques.
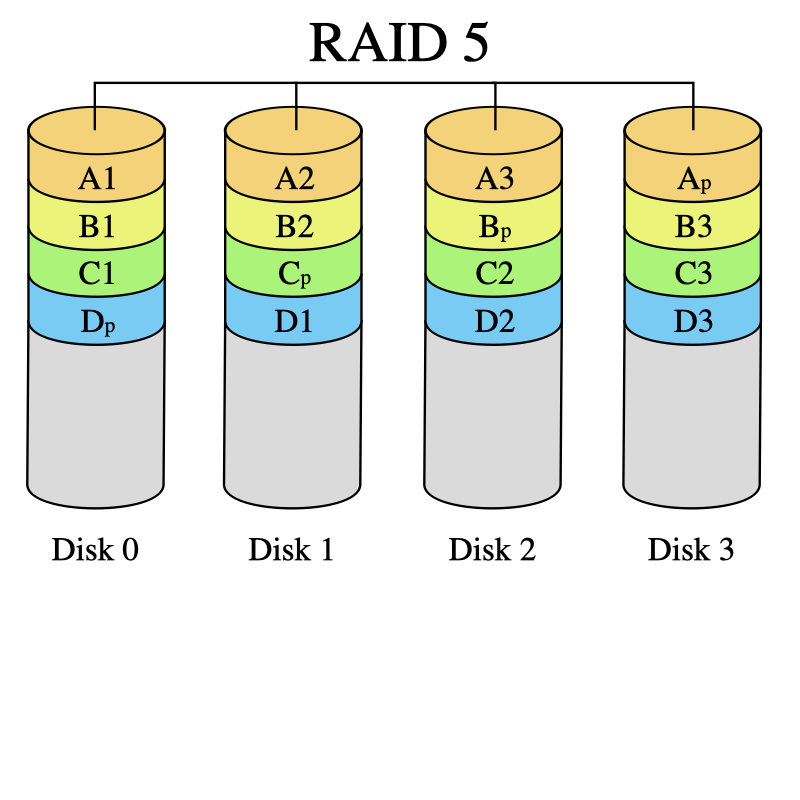
On voit donc que le RAID 5 ne supporte la perte que d’un seul disque à la fois. Ce qui devient un problème depuis que les disques qui composent une grappe sont de plus en plus gros (1 To et plus). Le temps de reconstruction de la parité en cas de disque défaillant est allongé. Il est généralement de 2 h pour des disques de 300 Go contre une dizaine d’heures pour 1 To. Pour limiter le risque il est courant de dédier un disque dit de “spare”. En régime normal il est inutilisé. En cas de panne d’un disque, il prendra automatiquement la place du disque défaillant. Cela nécessite une phase communément appelée “recalcul de parité”. Elle consiste pour chaque bande à recréer sur le nouveau disque le bloc manquant (données ou parité).
Bien sûr pendant tout le temps du recalcul de la parité le disque est disponible normalement pour l’ordinateur qui se trouve juste un peu ralenti.
Ce système nécessite impérativement un minimum de trois disques durs. Ceux-ci doivent généralement être de même taille, mais un grand nombre de cartes RAID modernes autorisent des disques de tailles différentes.
La capacité de stockage utile réelle, pour un système de X disques de capacité c identiques est de (X-1) fois c. En cas d’utilisation de disques de capacités différentes, le système utilisera dans la formule précédente la capacité minimale.
Ainsi par exemple, trois disques de 100 Go en RAID 5 offrent 200 Go utiles ; dix disques, 900 Go utiles.
Ce système allie sécurité (grâce à la parité) et bonne disponibilité (grâce à la répartition de la parité), même en cas de défaillance d’un des périphériques de stockage.

2. Logical Volume Manager LVM
Documentation : https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Logical_Volume_Manager_Administration/index.html
LVM est un ensemble d’outils de l’espace utilisateur Linux pour fournir des commodités de gestion du stockage (volumes).
LVM (Logical Volume Manager) répond principalement aux besoins :
- d’évolutivité des capacités de stockage
- tout en assurant la disponibilité du service.
Plus simplement il s’agit de redimensionner un système de fichiers (FS) dynamiquement (en augmentant ou en réduisant le nombre de disques physiques disponibles) avec un minimum d’interruption.
On utilise communément LVM en version 2. Le cas échéant, on sera invité à installer les outils de l’espace utilisateur nécessaires.
2.1. Prise d’information
La commande lsblkvous indique la manière dont vos disques sont montés. Aussi, la commande df -hvous donne des informations utiles.
2.2. Cas d’usage
On peut illustrer la fonctionnalité LVM dans le cas suivant.
Habituellement, un disque est constitué d’une ou plusieurs partitions :
- soit montée en racine unique d’un système,
- soit qui héberge le point de montage d’une application (
/home,/var/www/html,/opt/nfs-share/, …) - ou une partition Swap
Comment étendre les capacités d’une partition qui a atteint le seuil d’occupation maximale du disque qui l’héberge ?
Par exemple, les partitions configurées occupent entièrement les 128Go que peut offrir un disque /dev/sda.
La solution sans LVM consisterait à copier les données du système de fichiers saturé sur le système de fichiers d’un nouveau disque de plus grande capacité ajouté. On peut aussi réaliser le redimensionnement avec des outils comme parted ou d’autres biens connus.
Quoi qu’il en soit, dans ce cas, on ne peut qu’imaginer le manque en disponibilité et en évolutivité de la solution de stockage.
2.3. Solution LVM
Sous certaines conditions, LVM autorisera un taux de disponibilité proche du maximum lors du redimensionnement du système de fichiers qui consiste souvent en une extension en capacité.
En supplément, LVM supporte deux fonctionnalités qui améliorent ces critères : le mirroring et les snapshots (voir plus bas).
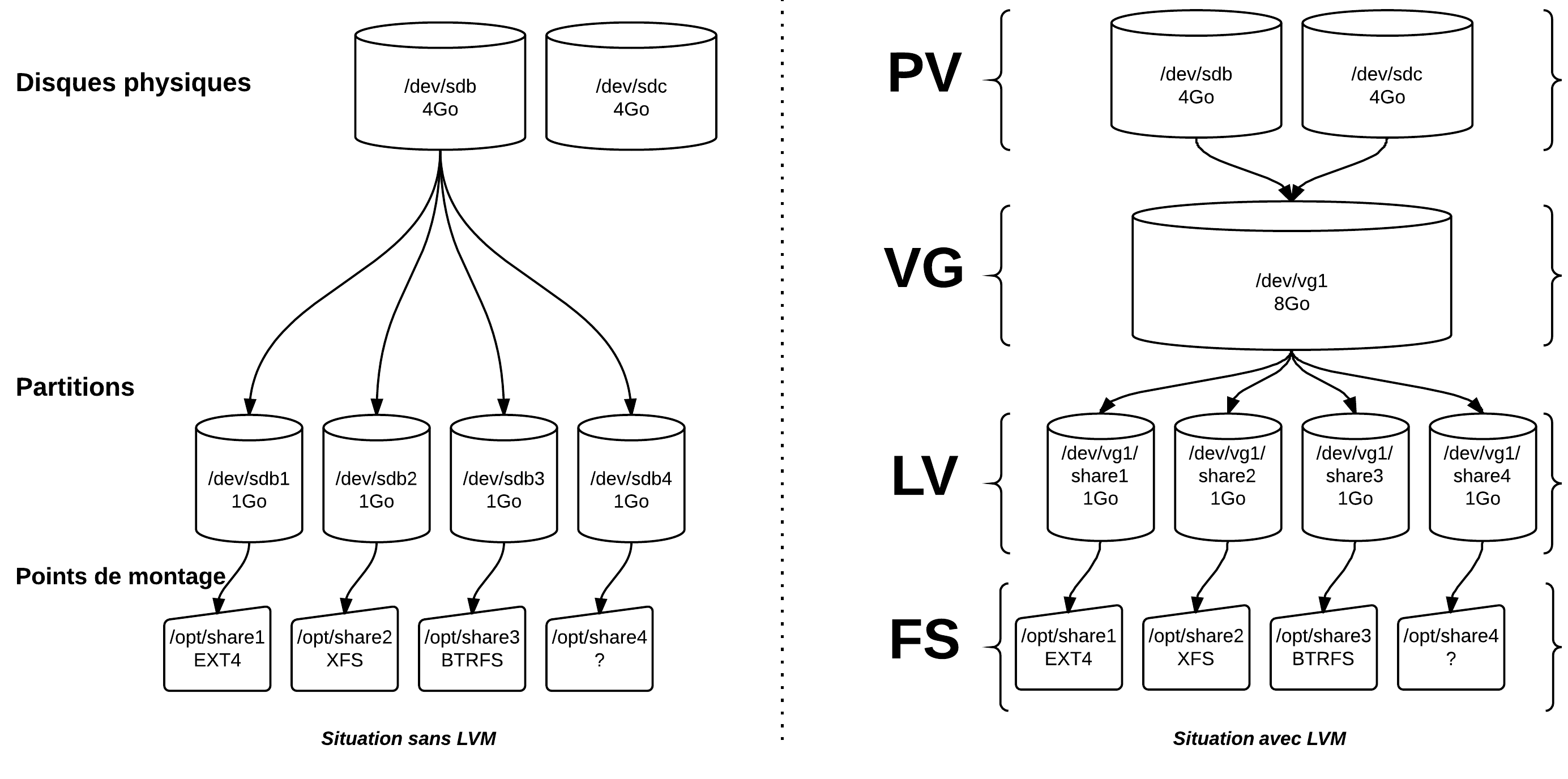
2.4. Concepts LVM
Système de fichiers LV VG PV
Avec LVM, le système de fichiers (FS : EXT4, XFS, BTRFS, …) est supporté par un Logical Volume (LV) au lieu d’être supporté par une partition ou autre périphérique. Un LV est un container de FS.
Les LV appartiennent à un Volume Group (VG). Un VG est une sorte d’entité logique qui représente une capacité de stockage.
Le noyau voit les VG comme des périphériques de type block (commande lsblk) et leurs LV comme leurs partitions. Ces périphériques sont dénommés par UUID, selon le schéma /dev/mapper/vg-lv ou encore selon le schéma /dev/vg/lv.
Un VG est constitué d’un ensemble de Physical Volume (PV). Les PV sont les périphériques physiques de stockage. Ils peuvent être :
- Un disque entier dont on a effacé le secteur d’amorçage (les premiers 512 octects du disque).
- Une partition d’un disque marquée par
fdisken type 8e. - Un fichier de loopback.
- Un array RAID.
Extents
Un PV est composé d’entités de 4 Mo par défaut que l’on appelle des Physical Extents (PE). Les Extents sont des blocs contigus réservé pour des fichiers sur un FS. Dans un PV de 4 Go, on dispose de 1023 PE par défaut.
Un VG est donc un potentiel, un stock, de PE disponibles. Un LV est composé de Logical Extents (LE) qui sont liés à un (1) voire plusieurs PE. Ces “metadonnées” de correspondance sont écrites et réservées au début de chaque PV. Dans un VG de 8 Go, on dispose de 2046 PE par défaut. Dans un LV de 1 Go, on dispose de 256 LE.
Un VG est donc un stock de PE (fournis par les PV) liés à des LE qui constituent le LV.
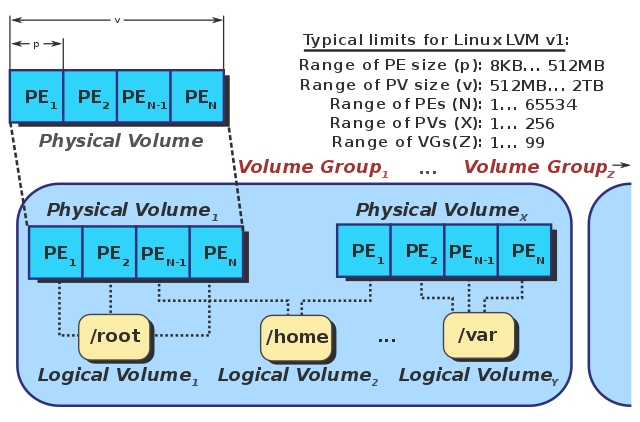
Source : https://commons.wikimedia.org/wiki/File:LVM1.svg
3. Opérations LVM
3.1. Installation et vérification
Installation
sudo apt-get install lvm2 || sudo yum install lvm2
Liste des commandes LVM
(sudo rpm -ql lvm2 | grep 'sbin' | sed 's/.*\/sbin\///g') || sudo dpkg -L lvm2
Vérifier la présence disques
sudo fdisk -l /dev/sda
sudo lsblk
sudo lvmdiskscan
3.2 Création d’un LV initial
Initialisation de PV
sudo pvcreate /dev/sdx
Visualisation
sudo pvs
sudo pvscan
sudo pvdisplay
Création d’un VG
sudo vgcreate vg1 /dev/sdx /dev/sdy
sudo vgs
sudo vgdisplay
sudo pvs
Création d’un LV
sudo lvcreate -L 8G -n lv1 vg1
sudo lvs
sudo lvdisplay
Point de montage utilisateur en EXT4
sudo mkfs.ext4 /dev/vg1/lv1
sudo mount /dev/vg1/lv1 /opt
Point de montage utilisateur en XFS
sudo mkfs.xfs /dev/vg1/lv1
sudo mount /dev/vg1/lv1 /opt
3.3. Miroring
Si les technologies RAID matériel et logiciel sont supportées par LVM et sont conseillées dans leurs meilleures versions selon les bons usages, alors un PV représente un array raid (/dev/md0 par exemple).
LVM offre une sécurité concurrente sinon complémentaire en proposant des fonctions de type RAID logique (linear par défaut, mirroring, stripping).
Les LE sont liés typiquement à deux PE sur des PV distincts, mais on peut créer 2 copies.
La création d’un journal de synchronisation peut consommer un certain temps. On conseille de le stocker sur un autre PV que celui qui abrite les données du miroir.
En cas de perte le PV utilise les PE restants. En cas de miroir simple (lvcreate -m 1), le LV fonctionne en mode linear (lvcreate -m 0 par défaut).
Faut-il aussi que le VG qui supporte des LV en mirroring dispose de suffisamment de ressources.
3.4. Extension dynamique
LVM permet de redimensionner des VG en leur retirant ou en leur ajoutant des PV (stock de PE). On peut alors redimensionner.
La disponibilité dépend des capacités du système de fichiers à se redimensionner dynamiquement sans démontage/montage. En 2015, EXT4, XFS et BTRFS supportent cette fonction.
On prendra certainement garde à réaliser une sauvegarde du FS avant un redimensionnement.
Le plus sûr est de :
- démonter le FS
- vérifier
- redimensionner
- vérifier
- remonter
Propriétés des système de fichiers
- EXT4 autorise un redimensionnement à froid (LV démonté) ou à chaud (LV monté).
- XFS se caractérise par le fait qu’il n’autorise que des extensions à chaud. Aucune réduction n’est possible.
- BTRFS permet une extension ou une réduction sur des LV montés ou non.
Extension à chaud en EXT4
df -h
sudo lvextend -L +1G /dev/vg1/lv1
sudo resize2fs /dev/vg1/lv1
sudo lvs
df -h
Extension à chaud en XFS
df -h
sudo lvextend -L +1G /dev/vg1/lv1
sudo xfs_growfs /dev/vg1/lv1
sudo lvs
df -h
3.5. Réduction
Réduction en EXT4 : démonté et vérifié
…
3.6. Remplacement d’un espace de stockage (disque SATA, partition) en mode linear
…
3.7. Remplacement d’un espace de stockage (disque SATA, partition) en mode mirorring
…
Passage en mode linear
sudo lvconvert -m 0
sudo lvs
sudo pvs
Réduction du VG
sudo vgreduce
Retrait du PV
sudo pvremove
Ajout du PV de remplacement (pas nécessairement identique à l’original) et extension du VG
sudo pvcreate
sudo vgextend
Reconstruction et vérification
sudo lvconvert -m 1
sudo lvs
3.8. Remplacement d’un disque d’un array RAID logiciel sur PV utilisé
Voir Cas 2.
3.9. Destruction
Destruction d’un LV
sudo lvremove
Destruction d’un VG
sudo vgremove
Destruction d’un PV
sudo pvremove
3.10. Snapshots
Réaliser un snapshot est l’action de prendre une image figée du LV.
A condition d’être montée, une copie du LV au moment de la capture reste accessible pendant une sauvegarde du système de fichiers. Cette copie est faite instantanément sans interruption.
A condition d’approvisionner en suffisance le VG qui héberge des snapshots, on l’imagine comme solution de clonage liés de machines virtuelles.
Ce n’est pas un sauvegarde exacte. Alors que le LV original continue à être accessible et à être modifié régulièrement, LVM enregistre les différences à partir du moment de la capture jusqu’à sa destruction. La permanence de l’instantané est maintenu par cette différence.
Autrement dit, sa dimension dépend des différences opérées jusqu’à la suppression du snapshot. Pour donner un ordre de grandeur dans la prévision de sa taille, un effacement complet du contenu du FS occuperait 100% du LV original. En général, 5 à 15 % peuvent suffire selon les transactions effectuées jusqu’à la suppression.
Le facteur temps joue aussi dans l’espace occupé par le snapshot.
Un snapshot est censé être temporaire. D’ailleurs, il s’efface lors du redémarrage du service.
sudo lvcreate -s
4. Cas 1 : Démo LVM
Configuration : distribution de base et 4 disques supplémentaires (sdb, sdc, sdd, sde) minimum voire plus ou à réutiliser.
Dans un premier temps, on tentera de comprendre la démo ci-dessous. Création de 4 espaces de stockage de 1 Go à des fins de partage dans un volume de 8 Go (2 disques)
- PV : 2 X 4 Go
- VG : 8 Go
- LV : 50 %
-
/opt/share1: 1 Go en EXT4 -
/opt/share2: 1 Go en XFS -
/opt/share3: 1 Go en BTRFS -
/opt/share4: 1 Go
-
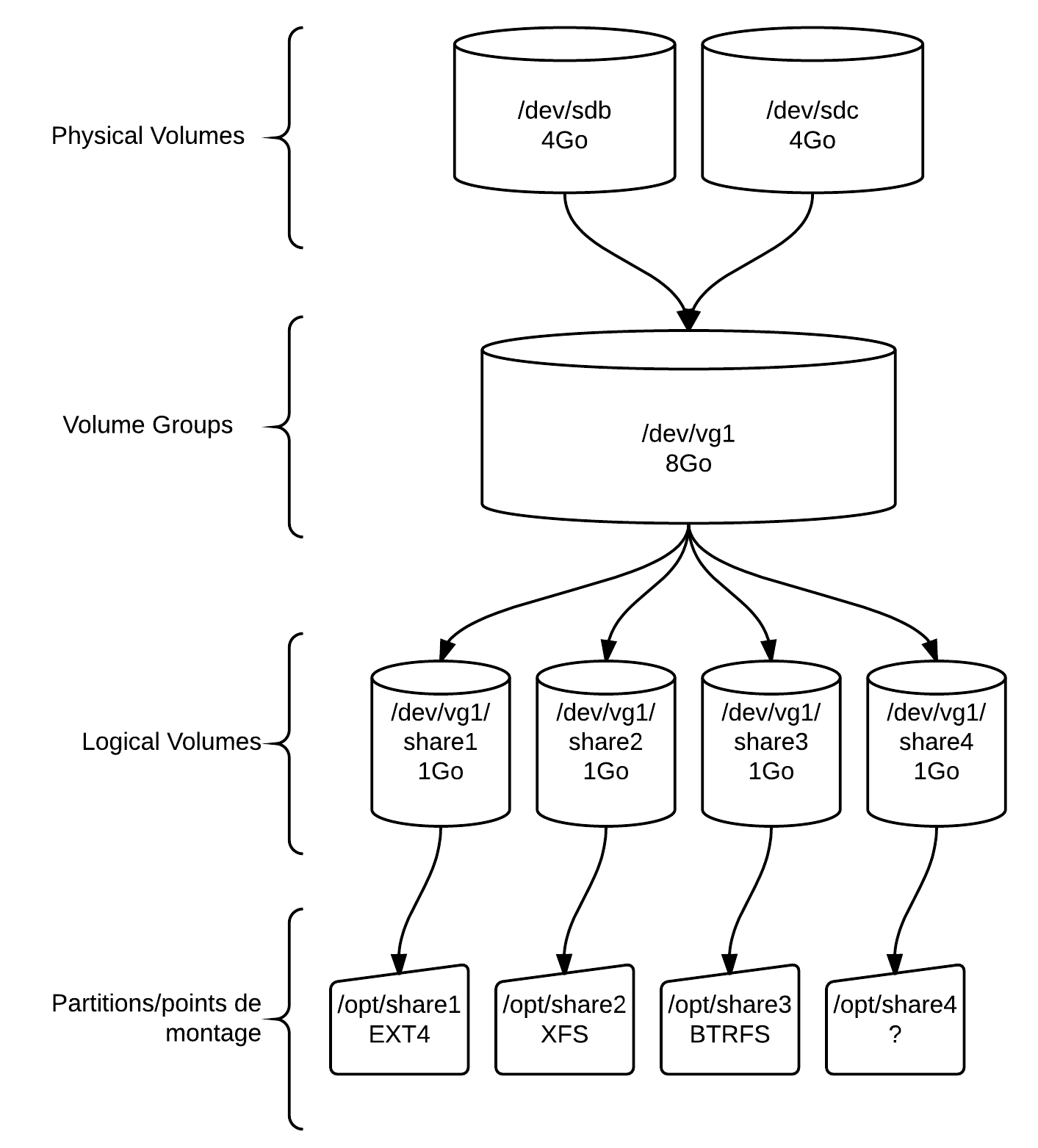
4.1. Phase 1 : Physical Volumes
Prise d’information
sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
fd0 2:0 1 4K 0 disk
sda 8:0 0 80G 0 disk
├─sda1 8:1 0 23,3G 0 part
├─sda2 8:2 0 2G 0 part [SWAP]
├─sda3 8:3 0 24,4G 0 part /
├─sda4 8:4 0 1K 0 part
└─sda5 8:5 0 20G 0 part /home
sdb 8:16 0 4G 0 disk
sdc 8:32 0 4G 0 disk
sdd 8:48 0 4G 0 disk
sde 8:64 0 4G 0 disk
sr0 11:0 1 1024M 0 rom
Création de PV
sudo pvcreate /dev/sd[b-c]
Physical volume "/dev/sdb" successfully created
Physical volume "/dev/sdc" successfully created
Scan de tous les périphériques LVM
sudo lvmdiskscan
/dev/sda1 [ 23,28 GiB]
/dev/sda2 [ 2,00 GiB]
/dev/sda3 [ 24,41 GiB]
/dev/sda5 [ 20,00 GiB]
/dev/sdb [ 4,00 GiB] LVM physical volume
/dev/sdc [ 4,00 GiB] LVM physical volume
/dev/sdd [ 4,00 GiB]
/dev/sde [ 4,00 GiB]
2 disks
4 partitions
2 LVM physical volume whole disks
0 LVM physical volumes
Vérification PV
sudo pvdisplay
"/dev/sdc" is a new physical volume of "4,00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdc
VG Name
PV Size 4,00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID p1NX9t-Q6zI-x93K-x8Zh-eMlB-ZG2j-daJ49X
"/dev/sdb" is a new physical volume of "4,00 GiB"
--- NEW Physical volume ---
PV Name /dev/sdb
VG Name
PV Size 4,00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 723B2y-ZwHK-OzZz-Nq3u-fkMc-Xd1I-ZeCPFD
sudo pvscan
PV /dev/sdc lvm2 [4,00 GiB]
PV /dev/sdb lvm2 [4,00 GiB]
Total: 2 [8,00 GiB] / in use: 0 [0 ] / in no VG: 2 [8,00 GiB]
Retirer/replacer un PV
sudo pvremove /dev/sdb
Labels on physical volume "/dev/sdb" successfully wiped
sudo pvscan
PV /dev/sdc lvm2 [4,00 GiB]
Total: 1 [4,00 GiB] / in use: 0 [0 ] / in no VG: 1 [4,00 GiB]
sudo pvcreate /dev/sdb
Physical volume "/dev/sdb" successfully created
sudo pvscan
PV /dev/sdc lvm2 [4,00 GiB]
PV /dev/sdb lvm2 [4,00 GiB]
Total: 2 [8,00 GiB] / in use: 0 [0 ] / in no VG: 2 [8,00 GiB]
4.2. Phase 2 : Volume Group
Création du VG vg1
sudo vgcreate vg1 /dev/sd[b-c]
Volume group "vg1" successfully created
Vérification du VG
sudo vgs
VG #PV #LV #SN Attr VSize VFree
vg1 2 0 0 wz--n- 7,99g 7,99g
sudo vgdisplay
--- Volume group ---
VG Name vg1
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 7,99 GiB
PE Size 4,00 MiB
Total PE 2046
4.3. Phase 3 : Logical Volumes
Création des LV
sudo lvcreate -L 1G -n share1 vg1
Logical volume "share1" created
sudo lvcreate -L 1G -n share2 vg1
Logical volume "share2" created
sudo lvcreate -L 1G -n share3 vg1
Logical volume "share3" created
sudo lvcreate -L 1G -n share4 vg1
Logical volume "share4" created
Vérification
sudo lvscan
ACTIVE '/dev/vg1/share1' [1,00 GiB] inherit
ACTIVE '/dev/vg1/share2' [1,00 GiB] inherit
ACTIVE '/dev/vg1/share3' [1,00 GiB] inherit
ACTIVE '/dev/vg1/share4' [1,00 GiB] inherit
sudo lvdisplay
--- Logical volume ---
LV Path /dev/vg1/share1
LV Name share1
VG Name vg1
LV UUID h4CES1-CK8z-Rusd-PbtY-N2uH-sXFE-IEgWrY
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2015-03-08 15:34:13 +0100
LV Status available
# open 0
LV Size 1,00 GiB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:0
--- Logical volume ---
LV Path /dev/vg1/share2
LV Name share2
VG Name vg1
LV UUID YzrnXb-DUNc-jKuf-RJvx-8P0s-yKdC-ZZ1Jm7
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2015-03-08 15:34:18 +0100
LV Status available
# open 0
LV Size 1,00 GiB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:1
--- Logical volume ---
LV Path /dev/vg1/share3
LV Name share3
VG Name vg1
LV UUID rLoohn-Vwzk-wgv7-GYjc-6jU3-Hc3x-7RdZkP
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2015-03-08 15:34:22 +0100
LV Status available
# open 0
LV Size 1,00 GiB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:2
--- Logical volume ---
LV Path /dev/vg1/share4
LV Name share4
VG Name vg1
LV UUID Yd0L8h-TZ7v-zUvj-6YYP-WBut-D3mn-GAZUaF
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2015-03-08 15:34:25 +0100
LV Status available
# open 0
LV Size 1,00 GiB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:3
4.4. Phase 4 : Formatage
EXT4
sudo mkfs.ext4 /dev/vg1/share1
mke2fs 1.42.9 (28-Dec-2013)
Étiquette de système de fichiers=
Type de système d'exploitation : Linux
Taille de bloc=4096 (log=2)
Taille de fragment=4096 (log=2)
« Stride » = 0 blocs, « Stripe width » = 0 blocs
65536 i-noeuds, 262144 blocs
13107 blocs (5.00%) réservés pour le super utilisateur
Premier bloc de données=0
Nombre maximum de blocs du système de fichiers=268435456
8 groupes de blocs
32768 blocs par groupe, 32768 fragments par groupe
8192 i-noeuds par groupe
Superblocs de secours stockés sur les blocs :
32768, 98304, 163840, 229376
Allocation des tables de groupe : complété
Écriture des tables d'i-noeuds : complété
Création du journal (8192 blocs) : complété
Écriture des superblocs et de l'information de comptabilité du système de
fichiers : complété
XFS
sudo mkfs.xfs /dev/vg1/share2
meta-data=/dev/vg1/share2 isize=256 agcount=4, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
BTRFS
sudo mkfs.btrfs /dev/vg1/share3
WARNING! - Btrfs v3.12 IS EXPERIMENTAL
WARNING! - see https://btrfs.wiki.kernel.org before using
Turning ON incompat feature 'extref': increased hardlink limit per file to 65536
fs created label (null) on /dev/vg1/share3
nodesize 16384 leafsize 16384 sectorsize 4096 size 1.00GiB
Btrfs v3.12
4.5. Phase 5 : Points de montage
Création des points de montage
sudo mkdir /opt/share1
sudo mkdir /opt/share2
sudo mkdir /opt/share3
sudo mkdir /opt/share4
sudo mount -t ext4 /dev/vg1/share1 /opt/share1
sudo mount -t xfs /dev/vg1/share2 /opt/share2
sudo mount -t btrfs /dev/vg1/share3 /opt/share3
tail -n 3 /proc/mounts
/dev/mapper/vg1-share1 /opt/share1 ext4 rw,seclabel,relatime,data=ordered 0 0
/dev/mapper/vg1-share2 /opt/share2 xfs rw,seclabel,relatime,attr2,inode64,noquota 0 0
/dev/mapper/vg1-share3 /opt/share3 btrfs rw,seclabel,relatime,space_cache 0 0
sudo findmnt
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda3 xfs rw,relatime,seclabel,attr2,inode64,noquota
├─/proc proc proc rw,nosuid,nodev,noexec,relatime
│ ├─/proc/sys/fs/binfmt_misc systemd-1 autofs rw,relatime,fd=32,pgrp=1,timeout=300,minproto=5,maxproto=5,d
│ │ └─/proc/sys/fs/binfmt_misc binfmt_misc binfmt_misc rw,relatime
│ └─/proc/fs/nfsd sunrpc nfsd rw,relatime
├─/sys sysfs sysfs rw,nosuid,nodev,noexec,relatime,seclabel
│ ├─/sys/kernel/security securityfs securityfs rw,nosuid,nodev,noexec,relatime
│ ├─/sys/fs/cgroup tmpfs tmpfs rw,nosuid,nodev,noexec,seclabel,mode=755
│ │ ├─/sys/fs/cgroup/systemd cgroup cgroup rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib
│ │ ├─/sys/fs/cgroup/cpuset cgroup cgroup rw,nosuid,nodev,noexec,relatime,cpuset
│ │ ├─/sys/fs/cgroup/cpu,cpuacct cgroup cgroup rw,nosuid,nodev,noexec,relatime,cpuacct,cpu
│ │ ├─/sys/fs/cgroup/memory cgroup cgroup rw,nosuid,nodev,noexec,relatime,memory
│ │ ├─/sys/fs/cgroup/devices cgroup cgroup rw,nosuid,nodev,noexec,relatime,devices
│ │ ├─/sys/fs/cgroup/freezer cgroup cgroup rw,nosuid,nodev,noexec,relatime,freezer
│ │ ├─/sys/fs/cgroup/net_cls cgroup cgroup rw,nosuid,nodev,noexec,relatime,net_cls
│ │ ├─/sys/fs/cgroup/blkio cgroup cgroup rw,nosuid,nodev,noexec,relatime,blkio
│ │ ├─/sys/fs/cgroup/perf_event cgroup cgroup rw,nosuid,nodev,noexec,relatime,perf_event
│ │ └─/sys/fs/cgroup/hugetlb cgroup cgroup rw,nosuid,nodev,noexec,relatime,hugetlb
│ ├─/sys/fs/pstore pstore pstore rw,nosuid,nodev,noexec,relatime
│ ├─/sys/kernel/config configfs configfs rw,relatime
│ ├─/sys/fs/selinux selinuxfs selinuxfs rw,relatime
│ ├─/sys/kernel/debug debugfs debugfs rw,relatime
│ └─/sys/fs/fuse/connections fusectl fusectl rw,relatime
├─/dev devtmpfs devtmpfs rw,nosuid,seclabel,size=7933072k,nr_inodes=1983268,mode=755
│ ├─/dev/shm tmpfs tmpfs rw,nosuid,nodev,seclabel
│ ├─/dev/pts devpts devpts rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=0
│ ├─/dev/mqueue mqueue mqueue rw,relatime,seclabel
│ └─/dev/hugepages hugetlbfs hugetlbfs rw,relatime,seclabel
├─/run tmpfs tmpfs rw,nosuid,nodev,seclabel,mode=755
│ └─/run/user/1000/gvfs gvfsd-fuse fuse.gvfsd- rw,nosuid,nodev,relatime,user_id=1000,group_id=1000
├─/tmp tmpfs tmpfs rw,seclabel
├─/var/lib/nfs/rpc_pipefs sunrpc rpc_pipefs rw,relatime
├─/home /dev/sda5 xfs rw,relatime,seclabel,attr2,inode64,noquota
├─/opt/share1 /dev/mapper/vg1-share1
ext4 rw,relatime,seclabel,data=ordered
├─/opt/share2 /dev/mapper/vg1-share2
xfs rw,relatime,seclabel,attr2,inode64,noquota
└─/opt/share3 /dev/mapper/vg1-share3
btrfs rw,relatime,seclabel,space_cache
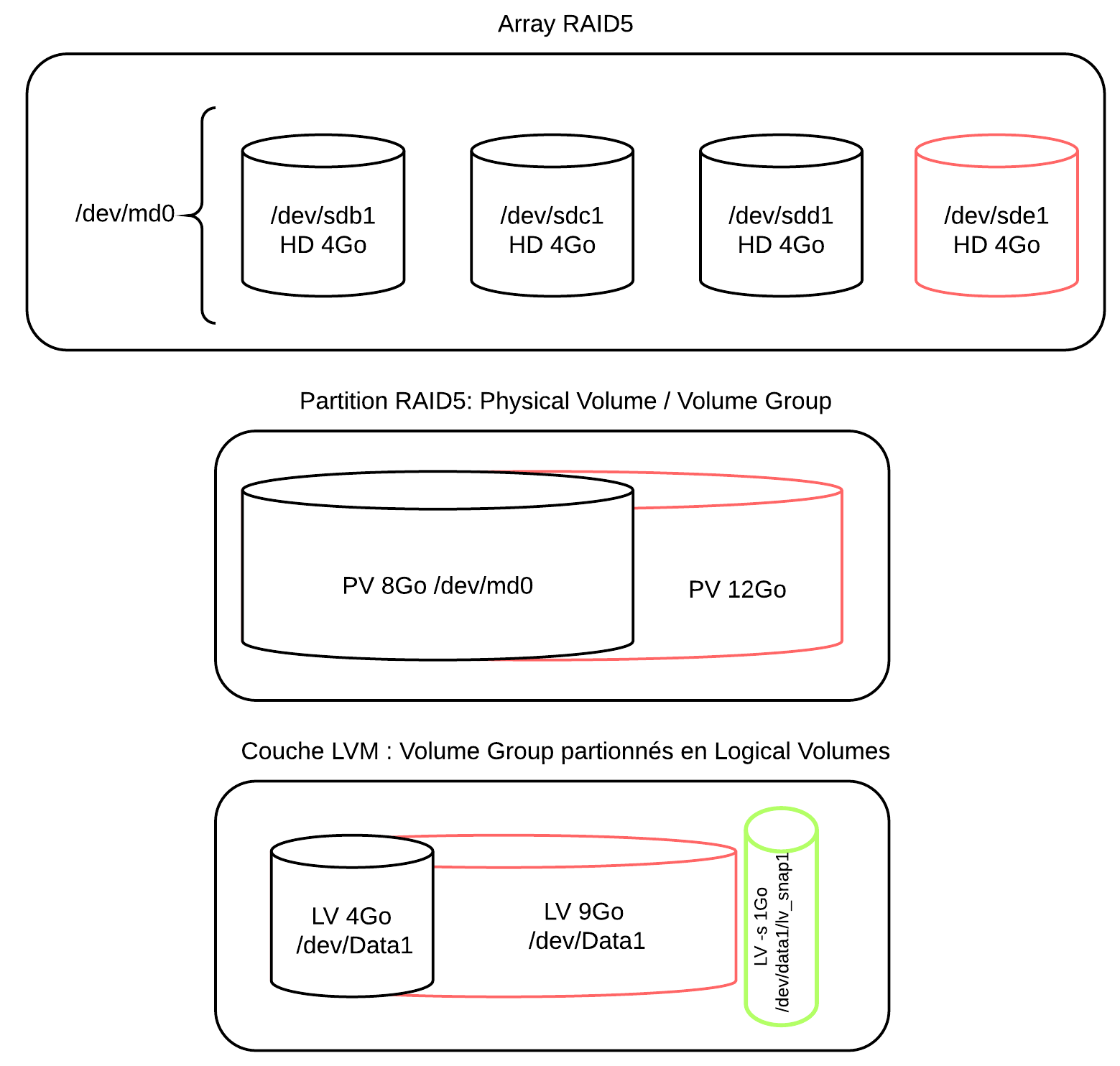
5. Cas 2 : RAID5 et LVM
Dans ce scénario que l’on reprend à titre démonstratif ou comme exercice on utilise des disques en RAID 5 logiciel. On peut utiliser les /dev/sdd et /dev/sde des cas précédents.
5.1. Scénario
Pour réaliser ce lab RAID LVM de base, une machine virtuelle Linux et un espace disque libre de 16 Go sur l’ordinateur hôte sont nécessaires.
Le lab consiste à manipuler cinq disques durs de 4Go (de taille égale si vous changez les dimensions) en RAID5 et LVM :
- soit créés dans le logiciel de virtualisation et attachés à la machine virtuelle
- soit créés “virtuellement sur le système de fichier de la machine virtuelle (sous condition que son disque dur dispose de suffisamment de capacité.
Le scénario est le suivant :
- Le premier disque (sda/vda/hda) est réservé pour le système.
- Un array RAID5 logiciel avec 3 disques est construit.
- Il est considéré comme un Physical Volume
- Une partition XFS (LV) est créée dans un Volume Group constitué de cet array. Elle est montée au démarrage dans le système de fichier.
- La manipulation suivante consiste à étendre à chaud la partition sur les trois disques en ajoutant un disque supplémentaire dans l’array.
- On peut créer des instantanés (snapshot) et les monter sur le système de fichier.
- Pourquoi ne pas forcer la reconstruction RAID en retirant le premier disque de l’array ?
- Enfin, on tentera de monter une stratégie de copies cohérentes instantanées avec LVM à l’aide d’un script.
- On imaginerait un scénario de création de partition à la demande (script).
- La prochaine étape consisterait à s’intéresser à de solutions d’automation de type cloud (stockage VM / containers).
- L’exercice peut aussi s’attarder sur les fonctionnalités riches de XFS (réparation, surveillance, quotas, support des disques SSD).
5.2. Schéma
5.3. Configuration de 3 disques de 4Go en RAID5 logiciel
sudo -i
apt-get install mdadm
ls /dev/{s,v,h}d*
Création d’une partion “fd (RAID Linux autodétecté)” pour chaque disque :
fdisk -l
fdisk /dev/sdb
fdisk /dev/sdc
fdisk /dev/sdd
Création de l’array :
mdadm --create /dev/md0 --level=5 --assume-clean --raid-devices=3 /dev/sd[bcd]1
Combien de capacité sur cet array ?
5.4. Configuration LVM à 4Go
LVM Adminsitration Guide RHEL6 (fr)
apt-get install lvm2 || yum install lvm2
- PV : Physical Volume ← point de vue physique
- VG : Volume Group
- LV : Logical Volume (FS) ← point de vue logique
1. Ajout de l’array dans un PV
pvcreate /dev/md0
pvdisplay /dev/md0
"/dev/md0" is a new physical volume of "7,99 GiB"
--- NEW Physical volume ---
PV Name /dev/md0
VG Name
PV Size 7,99 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0-
PV UUID AxIQeZ-W0CB-Fhld-pw9q-UiLR-0b5i-HRP0E3
2. Création du VG
vgcreate data1 /dev/md0
Volume group "data1" successfully created
vgdisplay data1
--- Volume group ---
VG Name data1
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 7,99 GiB
PE Size 4,00 MiB
Total PE 2046
Alloc PE / Size 0 / 0
Free PE / Size 2046 / 7,99 GiB
VG UUID u82fND-XNE6-h39B-PPtF-6if3-heYn-Tq3X5n
3. Création de la partition de 4G
lvcreate -n Vol1 -L 4g data1
Logical volume "Vol1" created
lvdisplay /dev/data1/Vol1
--- Logical volume ---
LV Name /dev/data1/Vol1
VG Name data1
LV UUID OPfKpH-fEid-1LOS-91Fh-Lp5B-qzs9-spK12n
LV Write Access read/write
LV Status available
# open 0
LV Size 4,00 GiB
Current LE 1024
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 4096
Block device 252:2
5.5. Système de fichier XFS
apt-get install xfsprogs
1. Formatage XFS
mkfs.xfs -L data1 /dev/data1/Vol1
log stripe unit (524288 bytes) is too large (maximum is 256KiB)
log stripe unit adjusted to 32KiB
meta-data=/dev/data1/Vol1 isize=256 agcount=8, agsize=130944 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=1047552, imaxpct=25
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =aucun extsz=4096 blocks=0, rtextents=0
2. Point de montage
mkdir /mnt/data1
mount /dev/data1/Vol1 /mnt/data1
df -h
Sys. de fichiers Taille Utilisé Dispo Uti% Monté sur
/dev/mapper/ubuntu-root 19G 1,3G 17G 8% /
udev 240M 4,0K 240M 1% /dev
tmpfs 100M 360K 99M 1% /run
none 5,0M 0 5,0M 0% /run/lock
none 248M 0 248M 0% /run/shm
/dev/sda1 228M 26M 190M 13% /boot
/dev/mapper/data1-Vol1 4,0G 33M 4,0G 1% /mnt/data1
Commande lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
Vol1 data1 -wi-ao--- 4,00g
touch /mnt/data1/test.txt
ou encore
dd if=/dev/urandom bs=1024 count=1000 of=/mnt/data1/fichier.bin
ls -l /mnt/data1/
Montage au démarrage
echo '/dev/data1/Vol1 /mnt/data1 xfs defaults 0 0' >> /etc/fstab
5.6. Ajout d’un 4e disque de 4Go
1. Création d’un partition /dev/sde1
fdisk /dev/sde
2. Ajout du disque dans l’array
mdadm --manage /dev/md0 --add /dev/sde1
3. Extension l’array sur les partitions
mdadm --grow /dev/md0 --raid-devices=4
4. Extension du PV
pvresize /dev/md0
Physical volume "/dev/md0" changed
1 physical volume(s) resized / 0 physical volume(s) not resized
pvdisplay /dev/md0
--- Physical volume ---
PV Name /dev/md0
VG Name data1
PV Size 11,99 GiB / not usable 512,00 KiB
Allocatable yes
PE Size 4,00 MiB
Total PE 3069
Free PE 2045
Allocated PE 1024
PV UUID AxIQeZ-W0CB-Fhld-pw9q-UiLR-0b5i-HRP0E3
5. Extension du VG :
Le VG ne doit pas être étendu avec la commande vgextend.
6. Extension du LV :
lvresize -L 9g /dev/data1/Vol1
Extending logical volume Vol1 to 9,00 GiB
Logical volume Vol1 successfully resized
lvdisplay /dev/data1/Vol1
--- Logical volume ---
LV Name /dev/data1/Vol1
VG Name data1
LV UUID OPfKpH-fEid-1LOS-91Fh-Lp5B-qzs9-spK12n
LV Write Access read/write
LV Status available
# open 1
LV Size 9,00 GiB
Current LE 2304
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 6144
Block device 252:2
df -h
Sys. de fichiers Taille Utilisé Dispo Uti% Monté sur
/dev/mapper/ubuntu-root 19G 1,3G 17G 8% /
udev 240M 4,0K 240M 1% /dev
tmpfs 100M 368K 99M 1% /run
none 5,0M 0 5,0M 0% /run/lock
none 248M 0 248M 0% /run/shm
/dev/sda1 228M 26M 190M 13% /boot
/dev/mapper/data1-Vol1 4,0G 33M 4,0G 1% /mnt/data1
7. Reformatage dynamique, extension du FS
xfs_growfs /mnt/data1
meta-data=/dev/mapper/data1-Vol1 isize=256 agcount=8, agsize=130944 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=1047552, imaxpct=25
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0
log =interne bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =aucun extsz=4096 blocks=0, rtextents=0
blocs de données modifiés de 1047552 à 2359296
df -h
Sys. de fichiers Taille Utilisé Dispo Uti% Monté sur
/dev/mapper/ubuntu-root 19G 1,3G 17G 8% /
udev 240M 4,0K 240M 1% /dev
tmpfs 100M 368K 99M 1% /run
none 5,0M 0 5,0M 0% /run/lock
none 248M 0 248M 0% /run/shm
/dev/sda1 228M 26M 190M 13% /boot
/dev/mapper/data1-Vol1 9,0G 33M 9,0G 1% /mnt/data1
5.7. Snapshot
Instantané d’un LV, se monte comme n’importe quel LV.
1. Fichier de test
touch /mnt/data1/pour_voir_snapshot.txt
2. Création d’un snapshot de 1Go :
lvcreate -L 1g -s -n lv_snap1 /dev/data1/Vol1
3. Suppression du fichier de test :
rm /mnt/data1/pour_voir_snapshot.txt
4. Montage du snapshot
mkdir /mnt/lv_snap1/
xfs_admin -U generate /dev/data1/lv_snap1
Clearing log and setting UUID
writing all SBs
new UUID = 15066bfc-556f-4c9c-a1d9-f0a572fc3e14
mount -o nouuid /dev/data1/lv_snap1 /mnt/lv_snap1/
ls /mnt/lv_snap1/
On peut aussi redimensionner, fusionner un snapshot.
5.8. Test RAID
mdadm --manage --fail /dev/md0 /dev/sdb1
mdadm: set /dev/sdb1 faulty in /dev/md0
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sde1[3] sdc1[1] sdd1[2] sdb1[0](F)
12572160 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [_UUU]
unused devices: <none>
Vous avez du courrier dans /var/mail/root
mdadm --manage --remove /dev/md0 /dev/sdb1
mdadm: hot removed /dev/sdb1 from /dev/md0
mdadm --manage --add /dev/md0 /dev/sdb1
mdadm: added /dev/sdb1
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdb1[4] sde1[3] sdc1[1] sdd1[2]
12572160 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [_UUU]
[=>...................] recovery = 8.7% (368720/4190720) finish=0.5min speed=122906K/sec
unused devices: <none>
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdb1[4] sde1[3] sdc1[1] sdd1[2]
12572160 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [_UUU]
[=====>...............] recovery = 27.4% (1152344/4190720) finish=0.3min speed=144043K/sec
unused devices: <none>
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdb1[4] sde1[3] sdc1[1] sdd1[2]
12572160 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [_UUU]
[=======>.............] recovery = 36.4% (1527132/4190720) finish=0.2min speed=152713K/sec
unused devices: <none>
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdb1[4] sde1[3] sdc1[1] sdd1[2]
12572160 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>
Notes
Automatisation
Partage
Afin de mettre en oeuvre nos compétences en administration et en automation du système, je vous propose un cas classique lié aux espaces de stockage.
Ces trois partitions vont héberger un partage entre plusieurs utilisateurs du groupe “omega”.
Chaque point de montage /opt/share[1-3] appartient au groupe “omega”. Ils sont partagés par deux utilisateurs “alfa” et “beta” appartenant au groupe secondaire “omega”.
Chacun de ces points de montage est accessible via le dossier d’accueil personnel de ces utilisateurs en liens symboliques. Par exemple /home/alfa/share1, /home/alfa/share2, /home/alfa/share3 doivent pointer sur les points de montage /opt/share[1-3] correspondants.
Les utilisateurs peuvent lire le contenu du dossier et ajouter ou modifier des fichiers.
Il est demandé de fixer le “sticky bit” et le “SGID” sur ce dossier en démontrant leur utilité.
Il est demandé d’automatiser l’ajout d’un utilisateur dans ce partage en vérifiant son existence préalables et en créant les liens symboliques uniquement si nécessaire.
